Enterprise Information Retrieval Needs
We have been searching computer-based collections of content in enterprises for fifty years. The price of storing/hosting content has plummeted, while the availability of content, particularly textual content, has skyrocketed, with the boom of audio, image and video content making their mark as well. But the amount of content is not the problem; in fact it is the greatest knowledge exploitation opportunity in history. The unmet challenge of this age is filling the users display device, eyes and intellect with every appropriate detail about his/her information need, in a form that is processible, digestible and succinct, and without his/her repeated asking.
The major elements of this challenge are:
Searching without borders.
Users with search needs must have a single access mechanism for all "enterprise" content; owned, licensed or "of interest". If every collection of content requires different signon, user interface, search request language and rules and result evaluation, it is a guarantee that most collections will be ignored in the normal (re)search process.

Cross-index or Multi-Index searching.
Even inside the firewall, users with search needs must have a single access mechanism for all "enterprise" collections. If proprietary engines cannot access their competitors' proprietary indices, and results, the complexity of enterprise search becomes hopeless…isn't it amazing that the audio/video media figured this issue out almost instantaneously?….and the dbms companies standardized ages ago.. probably because the ES technical and business models are archaic…stemming from the 1960s.
Search "Verticals"
Search needs to be an application that is dictated by the needs of each related group of users….the community-of-interest…by the taxonomy, the search features, the sources, the results analytics.
In-depth interpretation/analytics of content.
Content needs to be treated according to its type, as its type and structure will greatly influence how it should be searched. What's more, the "evidence" that makes a document interesting is typically very concentrated, and users shouldn't have to find the evidence… it should "find" them. Currently, at the document level, every word in the document, in structured fields or the body is indexed for speed and evidence highlighting. But in virtually every case, the documents are treated as an indistinguishable mass…e.g. an email message is the same as a 500 page report is the same as a web page.
Meaning uniformity
(Search)term meaning is still left entirely to the user, to interpret AFTER the search by examining the results…. Painstakingly.
Ease of expressing search needs
After 50 years, the average size of a user search expression has increased from one word (NOT one meaning!) to 1.3 words….hardly a pat on the back to the ES software vendor community.
II. The Nature of Enterprise Search and Federated Search
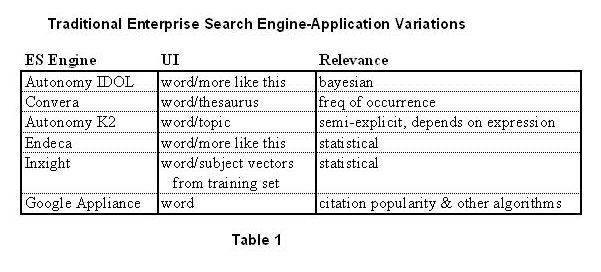
The meaning of Enterprise Search (ES) is typically understood as "full-text search used by and within the enterprise" It is the historical "information retrieval" for something beyond the personal filesystem, and developed its name to distinguish it from Internet (Web Page) search engines such as Yahoo, AltaVista and Google. It is characterized by:
- One or more collections inside the firewall that a single search engine full-text indexes (retrieval speed optimization and for result evidence highlighting) and search enables, via a engine-specific language and interface; each search engine used in this way inside the firewall is considered part of enterprise search….in a typical large multinational enterprise, we should expect a dozen or more ES configurations.
- Although not absolutely limited, ES generally addresses enterprise content within the firewall, or logical/secure enterprise boundary.
- Almost entirely a static, user-seeks-information-and-receives-results model.
- A wide variety of content styles (pdf, word, spreadsheets etc) are supported, but the only search model is text….there is no model for audio, graphics, image, video.
- It generally does NOT include DBMS-type search; structured data management and search are a separate business addressed by separate products.
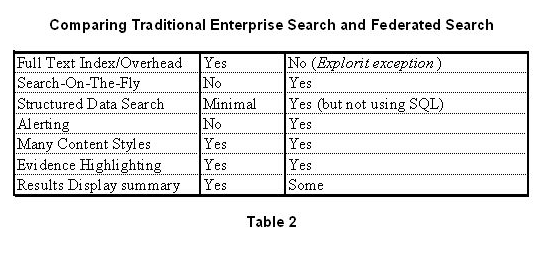
Federated search (FS) is simultaneous multi-collection; multi-engine access, non-indexed search, within and without the corporate firewall. FS has gained most of its popularity in the academic/public library space. While current industry analysts consider FS a part of ES; in fact its purposes, approach and power enable it to be not only a viable separate entity, either driving the acquisition of content for ES purposes, or being the true ES, with traditional ES becoming an post-search text analytic technique. FS is characterized by:
- No index; simultaneous searching of sources is done on-the-fly.
- Every ES collection is searchable.
- No boundaries; EVERY COLLECTION ON THE PLANET is searchable, via source – connecting and source-exploiting logic for each source; whether within the firewall, or an outside subscription source, or a surface web, or a deep web collection.
- Speed, particularly for Web-based collections, depends on the access / signon / speed characteristics of the specific site, and can be hidden only to a degree (faster sites results are presented before slower site results)
- Sources are selectable; a first order attempt and application specificity
- Generally, only titles, abstracts, snippets and other fields are evaluated, and fields vary by site. So FS is SUITED to collections with these features.
- More frequently than ES, users may employ an "alert" search expression and be notified when relevant results match their expressed need.
Many industry pundits have labeled FS as "slow" by using the Google "Time-To-Result-Set" metric. This comparison is a mistake, as the two are very different applications with very different audiences. First of all, FS is a method for accessing ALL content, and even if there is a price of a few extra seconds, or even minutes, the benefit of a true world-wide search scope far outweighs the clock time of interactive result list generation. Secondly, the far more effective way to use FS is to use it as a smart alert function, with each search request constantly monitoring the world of content sources for new and interesting material and delivering the content once discovered. Thirdly, the FS ability to source select and normalize all-source results with practical, meaningful evaluation-ranking overcomes the "I'll see what everyone else sees" mentality of the "citation-popularity" method of consumer web engines. Fourthly, the Google "popularity contest" utility on enterprise material, that has no links, is non-existent.
III. What Traditional Enterprise Search Lacks
Traditional ES makes its customers with true enterprise needs suffer. Incompatible, widely varying approaches insure that the search user gets LIMITED BENEFIT FROM THE application and is discouraged from investing in it further. While each of the areas described in Paragraph II above indicate areas lacking in ES, this paper concentrates on search scoping only. Every investment in traditional ES by the enterprise guarantees that the user experience will either be unaffected or complexity will increase. ES by its very implication must be an ENTERPRISE APPLICATION and have:
- A single search that accesses all possible sources of useful material
- Access and uniformity-of-access across collections indexed by other(s) means
- Ability to discover information beyond the firewall, and ability to DISCOVER information period
- Community-Of-Interest-specific application characteristics
IV. Deep Web Technologies/EXPLORIT has BECOME the Enterprise Search
Explorit, as the FS application with the broadest and deepest capability set, is the true enterprise search application. Its input is the entire world of content (by source) and its output is (1) the direction to full-text indexers inside the firewall about which content to keep and analyze further, and (2) search results enabling the review and/or retrieval of relevant material. Explorit uniquely among FS applications indexes content for full-text searching when necessary.
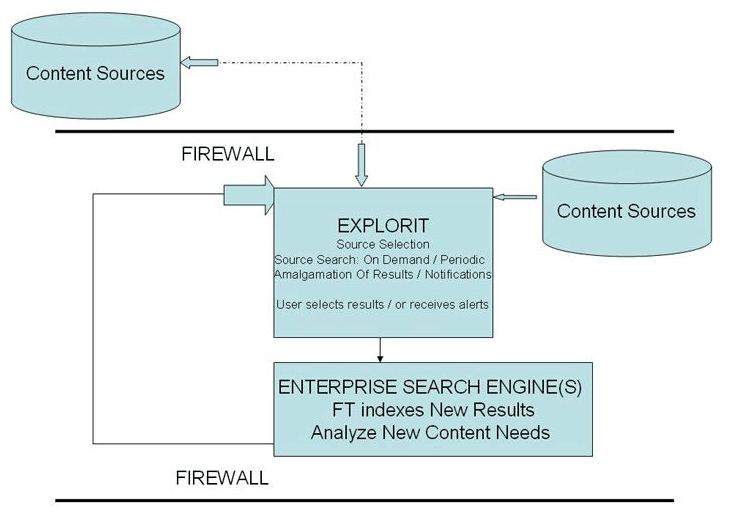
The characteristics below not only make FS/Explorit an important enterprise application in its own right, but provide the foundation for FS/Explorit to be the true enterprise search application leader going forward:
- FS/Explorit is the only way to guarantee that all subject-relevant material is located/discovered. Explorit uniquely exploits each of the sources it accesses for the fields, and search features supported. Explorit further normalizes all results and relevance-ranks them according to a practical, repeatable, controllable method.
- Explorit is an enterprise integrating application, linking all content/database collections (traditional indexed collections, content management/document management systems; data bases, web, deep web, subscription collections)
- Explorit extends the enterprise for search purposes outside of its borders/firewall
- Explorit is indifferent to which engines are inside the enterprise, and so it is every third party's friend, but particularly the enterprise's friend, because existing ES investment is protected. No re-indexing; no changes to existing engines.
- FS/Explorit maximizes use of subscriptions by including them in every search request.
- Explorit's community-of-interest model/architecture/strategy (gee, isn't an enterprise a community of interest?) enables source selection, custom interfaces and taxonomies, custom ranking, fields etc…
- Explorit enables/expects each search request to become an alert for one or multiple users, so in effect, the search is executing constantly against newly arrived material in each of the sources, with the discovery of new relevant results crating a notification to the user of their availability (and their relative fit with results seen previously)
- FS/Explorit identifies content for further analysis (including traditional ES bringing inside the firewall and indexing)
- Explorit is a Web Services model toolkit, able to be deployed within the enterprise web/search interface policy. Further Deep Web technologies is an experienced community-of-interest search site developer, implementer and operator/manager, so applications will be supported by the entire spectrum of implementation expertise and customization.
V. Risks/Flaws with FS Becoming the "TRUE" ES.
The risks are mainly political. Traditional ES engines are going to fight it tooth and nail. They're going to holler "too costly", "too complicated"….too "not us!". They may even have legitimate concerns such as…
1. What if there aren't any fields? Explorit could full-text index too.
2. FS is too slow. If you can't wait 10 seconds or 10 minutes for the answer, the purpose of your search can't have many long term implications (of course the boss could have demanded an immediate "answer"). See II above.
3. What if the interesting content isn't "available" Well, GET IT!
The main risk is an attitude adjustment. The only way to achieve TRUE Enterprise Search is to insert/use a seamless, interoperable WWW 2-compatible, mature universal search application that preserves every dime of previous ES investment.
VI. Still on the Horizon
The FES application is ready; it's time to adopt it. If FS was perfect, or even if FES was perfect, this paper would be the first to state it. In adoption-integration, several factors need to be considered.
- How to exploit FES when summaries and snippets don't exist. In the collections where they appear, they are better predictors of fitness to a particular search expression than the full text, and how to compare FS relevance with (post-process) engine full-text relevance.
- Seamlessly and securely incorporating CMS/DMS collections in the Federated Enterprise Search process, including their security and access limitations, with discretionary access control provided by existing, proven approaches.
- Cross-engine relevance determination models, to understand how the same content is evaluated by the industry of engines
- Full-text Indexing at the appropriate unit of text for retrieval optimization; and accompanying display of the larger context around the evidence locations (i.e. next/previous page/paragraph/section)
- Effortless User interface advancement via searchable explicit taxonomies and other devices, including community-of-interest networks.