Mapping Security Requirements to Enterprise Search - Part 3: Problems to Look Out For
Introduction
In the first two installments of this series we covered:
Part 1: http://ideaeng.com/security-eprise-search-p1-0304
- Introduction to adding security into Enterprise Search engines
- Defining some of the vocabulary that will be used
- Examined some of the search related requirements companies have
Part 2: http://ideaeng.com/security-eprise-search-p2-0305
- Defined some key vocabulary terms
- Design of Early-Binding Document Security
- Design of Late-Binding Document Security
- Links to specific Vendors and the names they have for their security feature
In this final installment we discuss some of the issues that can arise when considering security. Things don't always go as planned, even during the design phase; hopefully we can give you a "heads up" on what to look out for earlier on in the process.
Non-Indexable Content and Federated Search
Revisiting a theme from the first installment, is a bit of a contradiction to including more and more of you data in the search engine's index, which also increase the chance that even a trusted employee might accidentally gain access to highly confidential information that they are not supposed to have access to.
In the last two installments we've talked about how to satisfy both goals by implementing robust document level security in your main search engine. But a core assumption in this design is that you are using a central monolithic search engine. The design assumes that then engine will be indexing all of the content into its own centralized search indices, and then perform filtering at search time. We refer to this as the "Über Index" design, one search engine indexing data from all of the repositories in the company, even the ones with sensitive data.
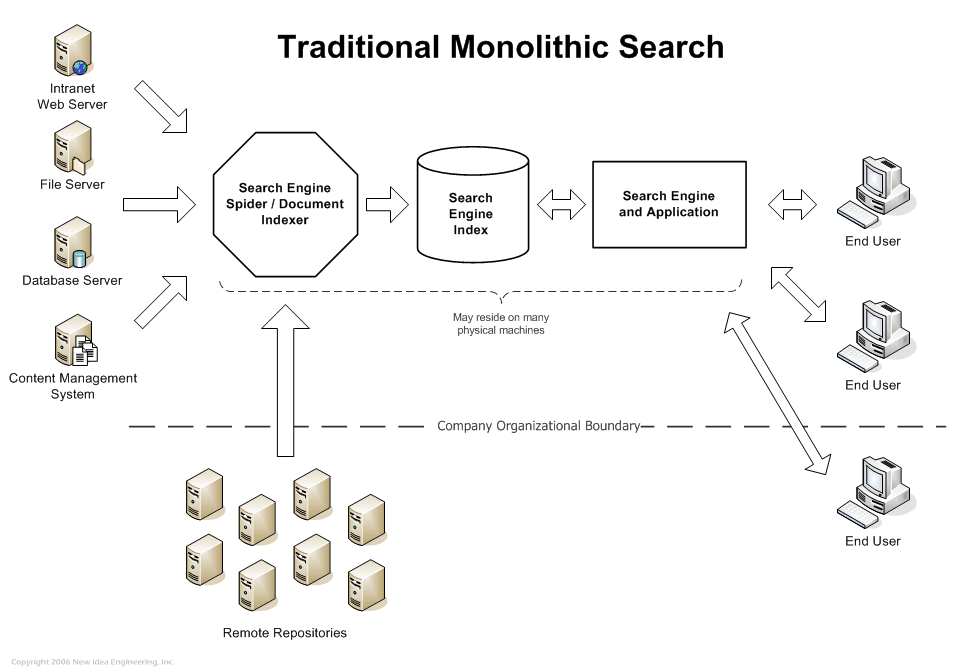
In some organizations this is simply not feasible. There may be technical obstacles, such as repository that no vendor directly supports and that lacks an export or web interface.
But business related issues can present intractable roadblocks, such as organizational boundaries or very tight security policies. For example, some groups may not want to provide the spider with a login that can access all of their content, even if they are promised that data will be filtered reliably at search time. Or, since a central search would technically be duplicating their secure data onto another computer in some format (cache files, binary search index, etc), that might violate a security policy that mandates the data remain solely in the original secured place.
For the latter business related obstacles, a thorough explanation of how search security works might change some minds, but certainly not all. Instead of "arm twisting", implementing Federated Search might be a palatable alternative.
Federated Search allows a user to enter a search into a single web form, but get back combined results from multiple separate search engines. When security is a factor, the authentication credentials of the user that are passed into the original system must be forwarded on to the remote search engines, so that they can also enforce document level security on their end. The advantage of this model is that, from the remote and highly secure search engine's view, the search can be treated just like a search submitted by a user directly to that engine. If the credentials are wrong, no results are returned; the remote search engine maintains control of its own security, regardless of where the search originated from.
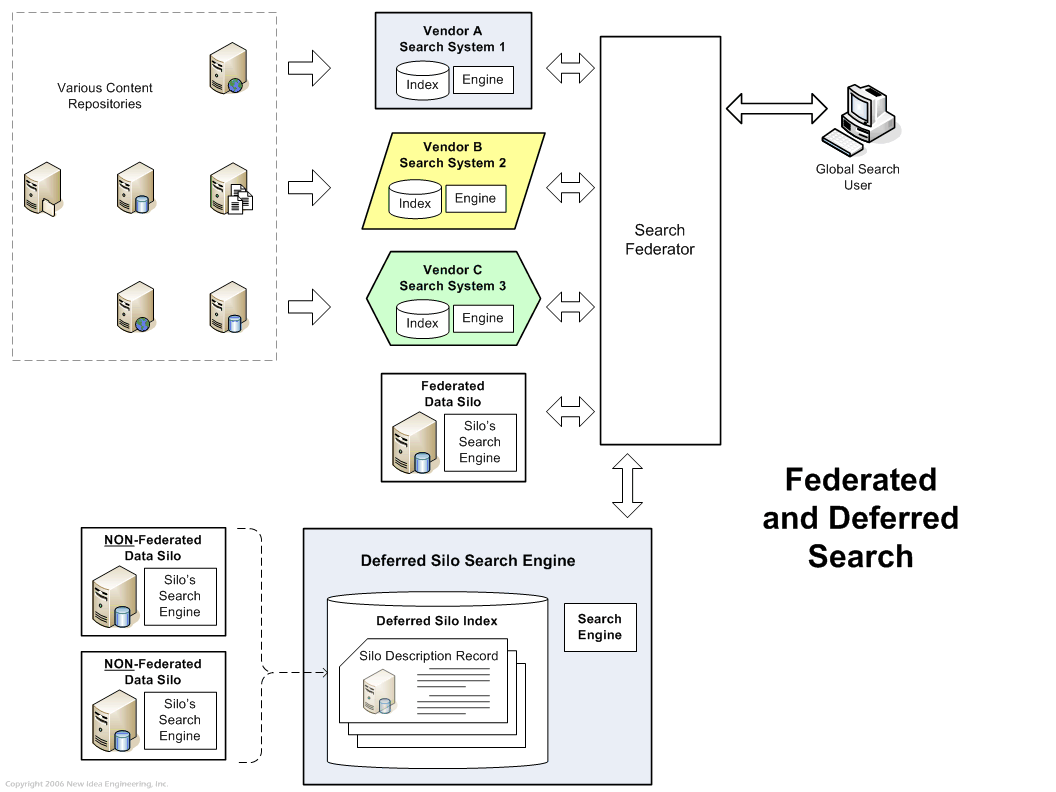
Matching URLs or records from the remote engines can be combined with the results from the central engine, into a single list of results. However, there may be technical and design issues with doing this. Another option is to keep the results from the various engines separate parts of the results page, either in separate tiles, different section headings, or even on separate tabs.
It's possible that some remote search engines will not even accept federated searches, for either technical or policy reasons. If there are number of non-federated sites like this, the sites themselves can at least be listed as suggested sources of data, if the description of the site contains matching terms.
As an example, if the finance department doesn't want financial records searched remotely at all, neither by uber indexing nor by federated search, a description of their site could at least be included. In this example, a user issuing a search for "budgets" would not get any specific finance document back, but they would see a suggestion to visit the finance department's web site, because the site's description included terms related to "budget".
Securing All the Links
Note: This section may be a bit terse for some folks; please email us if you need a more detailed explanation.
Search engines interact with many other systems and users over the network, usually via TCP/IP sockets. Hackers often try to monitor these communication channels; highly secure environments will need to encrypt or protect these communication channels by some means.
Some of the typical socket traffic would include:
· From the Spider to the Repository
· From the Client to the Application Server
· From the Application Server to the Search Engine
· From the Search Application or Engine to data logging services, such as when searches are being sent into a Search Analytics Database table.
How Are Links Secured?
Detailing this is beyond the scope of this article, but we can at least point you in some specific directions.
A common way to secure sockets is by changing from http to https, using SSL, or employing other encryption techniques.
If it is too difficult to secure all the sockets, machines could be organized into a secured subnetwork or DMZ, protected by a firewall.
Traffic from other sources might be handled via a proxy server or "reverse proxy server". One open source resource that can help with some of these tasks is the Squid caching proxy server from the Apache group (http://www.squid-cache.org/)
Data Stored on Disk
Securing the Search Index
Every search engine stores information about the source documents it has indexed or Spidered in some type of local database, stored as a series of large binary files on disk or network storage. These files contain titles, summaries, and a catalog of all the words in the source documents. Some systems even include large snippets of the documents' text, or may have even cached the entire document itself. Even a search engine that ONLY contains word instance information is still technically dangerous – it is possible to partially reconstruct source documents using only word instance information; this is not science fiction, it can and has been done.
We suggest simply locking down any servers that have access to these disk files. There is talk of encrypted search indices, or solutions that will encrypt an entire file system, but we worry that this will slow down performance and complicate implementation efforts; this practice is certainly very rare.
Scripts, Logs and Stored Passwords
As with many other software products, the startup scripts, indexing scripts and spider configuration files can contain passwords. Some vendors to support storing hashed passwords, so that at least the passwords are not stored as plain text. However, as with search indices, these disk files should only be available to machines that are tightly secured.
Results List Gotchas
Titles and Summaries can be a Leak
As we warned about in the first installment, results lists should not reveal anything about documents that a user isn't allowed to see. Securing the document itself, but still showing titles and summaries to a user, is a real security breach and wanted to repeat the warning here.
Navigators and Statistics Can Reveal Sensitive Items
Another reminder from our first installment, results lists should not reveal anything about the words that are in documents that a user is not allowed to see. Results lists often show how many matching documents there are, or how many documents contain each search term, or provide clickable hyperlinks to drill down into the results.
As an example, "layoffs" is a very loaded term; even if an employee doesn't get any documents listed in their results list for that search, a "helpful" navigator that confirms the existence of documents with that term, or worse, how many documents have that term, is still a security breach; that employee might assume that layoffs are, in fact, on the way!
This level of security may not be easy to reach with some vendors. Please check with your vendor carefully if this is a concern.
Highlighted Document URL Linkage = CGI Back Door
There are some very handy and innocent looking features in results lists that can sometimes be hacked and used to bypass security.
For example, when a user clicks on a document in a results list, many search engines open up the document and show search term highlighted WITHIN the document, instead of sending the user to the original document URL. This is referred to as Document Highlighting, which should not to be confused with highlighting search terms in the results list's document summaries.
Related features include the ability of some search engines to convert various document formats into HTML, by offering some type of "View as HTML" link. Also, some search engines may fetch matching records from a database, and display them to the user.
In all these examples, the search engine is accessing the source document again, long after indexing is complete, every time a user wants to view the document. More importantly, these are usually implemented by using clickable URLs that point back into the search engine; these URLs can be edited to access OTHER documents, ones the user should not have access to.
In other words, even if a user doesn't see a secured document in their results list, they can copy one of these utility URLs to an editor, change the document ID, and then paste the modified URL back into the web browser. If security has not been implemented properly, the search engine will obey and retrieve and display the blocked document.
More modern systems are aware of this type of trick, and these secondary links are also validated against the user's credentials. Older systems might use a single "super" login to fetch documents for highlighting, and thus enabled hacking.
In reality, we've never seen a user actually do this, even on the older systems. Search engines seem rather complicated to most users, and editing URLs takes a bit of technical skill. But thorough security doesn't rely just on "security through obscurity".
Runtime "Super" Login
Separating out and repeating what we mentioned in the previous section, some older search engines had one or more super logins for the runtime search engine; this was used at search time, not just at index time. If your system requires this type of login, please re-read the previous section carefully and make sure you understand it.
Admin Gotchas
Securing the Admin!
It amazes us, but some search engines' default installation brings up an administrative service with no password! In reality, the software is usually on a private network, so this practice is slightly less dangerous than it sounds. But there's tendency for folks to forget to correct this, and a year later it may still be unsecured. ‘nough said?
Secure the Search Analytics and Business UIs as Well
Also, many search engines have more than one administrative administration UI. They may have a UI for IT, another UI for business owners, or perhaps even a third UI for running reports. These should also have passwords.
Capturing User Info in Search Logs
From a technical standpoint, it's nice to have information about which user did what search in the search logs. By tracking the ID of each user's search, a Search Analytics package can show trends on a per-user or per-group basis.
However, some sites may have security policies that forbid this type of data gathering, so those sites should make sure to disable this feature. Also, some government jurisdictions may place restrictions on tracking user activity.
A gray area, for sites concerned with privacy, is that the TCP/IP address of the computer doing a search is often tracked. If the computers have fixed IP addresses, or tend to get the same address when they are rebooted, it might still be possible to track searches back to a particular user. From a reporting standpoint this is handy, but again it may violate a company policy or government regulation.
Conversely: Not Capturing User Info in Search Logs
Assuming there is no policy or law forbidding the logging of employee or customer search activity, then it should be properly logged. Not doing so could cause problems later.
For example, suppose the Tech Support manager notices a sudden cluster of searches in the reports, such as "crashing", "software crashing", "software crashes", "core dump", "your software sucks", etc. It's likely these all came from the same frustrated customer - but which customer? If that info hasn't been logged, then the manager can't proactively provide relief or account management.
Similarly, perhaps an HR manager suddenly notices a bunch of searches such as "sexual harassment", "sexual harassment policies", "reporting sexual harassment", etc. Clearly some employee seems to have some concerns or questions about this subject but has not specifically come forward to report anything. If the HR manager knew who that employee was, they might want to start some preliminary investigations.
Though we are not lawyers, some recent sexual harassment rulings seemed to center on whether or not a victimized employee actually reported the abuse to management or not. The implication being that if the employee did NOT report the abuse, then the company should not be held liable for failing to address it; how can an employer fix a problem that they don't know exists?
We speculate that, at some point in the future, a court might decide that sexual harassment related queries submitted to the HR site were in fact a means of "reporting" the problem. If that were to happen, then a company might then become liable if they failed to notice the searches and take action. So being able to trace these searches back to a particular user may become a legal requirement.
Raw Search Logs or Search Reports Could Reveal Sensitive Data
We've touched on a related area a bit earlier, but if a casual user of the reporting toolkit were to suddenly see lots of query activity about a layoff in the search logs, they might infer that a layoff is coming. Seeing search terms doesn't always mean that there was matching content, but it can certainly infer it; and some engines will confirm how many documents matched. If an analytics tool were to report that it was the CFO searching for layoff material, and did he in fact get 150 matches, a report user would have even more angst.
User Info
If an identifiable user has many searches for a particular subject that might be embarrassing, an inconsiderate coworker might let others know. For example, an employee might be looking for information in the HR database about policies related to sexual orientation or gender reassignment surgery; a coworker viewing those searches in a report might be very surprised by this and have trouble respecting confidentiality.
Ping / Sanity Checks
As part of ensuring the search engine is running correctly, we suggest that clients run an advanced "ping" script to periodically run a know search and check the actual results.
This is a good idea, but it not properly filtered out, it will add lots of bogus entries to the Search Analytics Reports. The ping script should identify itself in some unique way. We don't have space to delve into the details on this one, drop us an email if you have questions.
Spider / Indexing Gotchas!
Spider and Repository "Super" Logins
If the sites your spider has access to require a login, then your spider will need a login. But unlike typical user logins, the spider's login will have complete access to all of the content. This super login must be treated carefully, and should be clearly disclosed to repository owners.
Detecting a Failed Page
The HTTP protocol clearly defines error codes that should be returned when a requested page cannot be accessed. The page may no longer exist, or this article's case perhaps a login is required.
However, web servers do not always use these codes, or do not make it clear to the spider that an error has occurred, or that a login is required. Even if your spider has a valid login for the repository it is trying to crawl, you may need to help it understand when that username and password needs to be sent. A symptom of such a problem is noticing that your results list has lots of titles and summaries that talk about logging in or instructions about resetting your password, etc., instead of having the titles and summaries for the real documents.
In the early days of the Internet, when a web server wanted a user to login, it would send an HTTP "challenged response" error code of 401 or 402. For a human operator, a small separate popup dialog box appears, and they are asked to enter their user name and password, and sometimes also a "realm" or "domain". 401 style challenged response is easy to recognize because you get a separate, popup window in your browser, that is clearly not part of a normal HTML page. Spiders generally do understand this type of response, and handle it correctly. However, more modern sites often don't use this return code. Instead they want to provide the user with a full web page that explains the problem, and the web page will include the login username and password boxes. This is the type of situation that spiders often have trouble with; they don't understand that his is NOT the page they just requested, and therefore it as a regular document.
False HTTP status 200 Codes
The most annoying version of this problem is when a server returns an HTTP success code of 200. The server returns an HTML page with an error message or a login form, but sends a return code of success.
It is our very strong opinion that this practice violates the RFC protocol for HTTP, or at least its intent. The requested page was not returned, but the server has reported 100% success. If there was an error, the server should be returning a 404 or 500 series error. If the user needed to login, then it should have returned a 401 or 402, or at least redirected to login page by sending a 300 series error code.
If you are trying to spider a site that returns OK/200 for failed requests, the administrator of that web site really should fix it. If it is within your company or organization, there's some chance they might listen.
However, if you have no influence of "false-200" sites, you will need to modify your spider to actually look for the login or error text in the HTML that is returned. Spiders don't usually have an option for this and you may need to speak with your vendor.
If you will be indexing lots of public sites, you might want to consider creating some custom spider logic that looks for these patterns by default, and takes appropriate action. This type of system could even be designed to read bad phrases from a file or database, so that non-programmers can easily update the lists. This would also be a good way to filter out other types of "bad content" as well:
· From above, "login" required / login forms
· "squatter sites" - domains that have not been registered and are "for sale")
· Sites that are "under construction"
· Objectionable or offensive content.
· Sites that use frames
· Sites containing no actual text
· Sites that require JavaScript, Java, Flash or some other technology to view the site
· Unsupported user agent errors
· Unsupported "referer" (sic)
· Unsupported HTTP or browser versions
Many of these sites will also report a misleading status of 200 to your spider.
Redirects to login pages
A somewhat easier problem to detect and fix is when a site requiring a login redirects the user to a login page. A return code in the 300 range is returned in the HTTP header, along with a "location" header field. Redirects are very common even for pages that don't require a login, so just looking for the HTTP 300 series return codes won't distinguish good pages from bad by itself, but it's a start.
Some spiders support "forms based login". When these spiders get a redirect, they check the target of the redirect ( the new URL is sent back in the location field of the HTTP header). They check this new URL against a list of known login forms. If the new URL points to the login form, the spider understands that it needs to login; if the spider does not recognize the redirect as a login form, it treats it like a normal redirect and attempts to fetch that new page.
Spider Revisiting Orphan Links
An "orphan link" is a web page that still exists, but is no longer linked to by the main site. If a user had bookmarked the URL for the page, then they could still get to it; but a new user, starting at the home page, would not be able to navigate to it.
This typically happens when a webmaster unlinks content on the web site; they decided that an area of content is obsolete, for example, and they remove all hyperlinks pointing to that section of the site. In the webmaster's mind, this content has now been effectively removed from the site, even though the specific files have not been deleted.
If a new spider were to crawl the site for the first time, after the links had been removed, the spider would never see those pages, and would not index them. However, a spider that crawled the site before the content was unlinked would still have a record of those pages, it would still have the URLs.
Some spiders will revisit these pages on an individual basis by URL, regardless of any changes to the links to those pages. Since they already have the URLs, and since those URLs still work, the spider will continue to index this orphaned content. A spider that operates in this mode is often referred to as an "Incremental Spider". Generally, revisiting each page individually is an advantage, because the spider can give more attention to pages that have been frequently changing, and only occasionally visit pages that almost never change. This issue of orphaned links is one of the few downsides to these Incremental Spiders.
This is not the case with all spiders; older spiders tended to start at the top of a site each time they ran, and reindex everything from scratch; those spiders are generally referred to as "Batch Mode Spiders" or "Non-Incremental Spiders".
To recap, if content is removed from your site by simply de-linking it, it may continue to show up in search results due to incremental spidering. To force this orphaned content out of your search index, you will need to take one of the following steps:
1: Actually remove the content, page by page, from the web server or repository.
2: Specifically remove each URL from the spider's link database; this may not be possible with some spiders.
3: Start a completely new spider of the site, one which starts with a completely empty links database. Look for options like "Full Reindex" or "Clear Collection".
There is one other related orphaned content problem worth mentioning, though not directly related to security. In rare cases, a webmaster accidentally unlinks content. This also creates orphaned content. If the web site uses an older spider, the number of pages in the search index will drop dramatically; hopefully the site will notice this large drop and fix it right away.
However, if a site accidentally unlinks content but is using a newer incremental spider, the spider will mask the mistake because it will continue to access the orphaned content by URL. On the surface this seems like an advantage, but this site now has 3 problems:
1: They have content that users can longer navigate to.
2: They don/t know about the problem and may not discover it for some time; since their spider is incremental there is not dramatic change to report from the search engine's standpoint. And
3: At some arbitrary point in the future, when they do reindex their site from scratch, the page count will drop dramatically and they may have trouble figuring out why. Since the content was accidentally orphaned months or possibly years ago, vs. more recent changes which have nothing to do with the problem, they may focus only on more recent changes and miss the real cause.
Spider Used File System Access, Got Unintended Files
Sometimes a company will decide to have the spider crawl a file system, such as a server's hard drive, to find documents to index. These documents are often also available on the web, so the document has both a file name and a URL, and the spider understands how to map one to the other. There are various reasons for wanting to use file system indexing instead of web indexing, including performance, but the detailed are beyond the scope of this article.
Since the spider can see all the files in every subdirectory, it will want to index all of them, regardless of whether or not those pages are linked to by other pages on the web server side. As an example, an author may have several versions of a document. Only the final copy is linked to on the web server, but when file indexing is done all 3 versions show up.
Another issue is that the web spider may have only been looking for HTML and PDF files, but many file system crawlers will also index Excel spreadsheets, Microsoft Word documents, Access databases, etc. by default. Those files are much more likely to contain sensitive information that was never intended to be published in any format. If you use file system indexing, you should run a report by Mime-Type, to make sure suspicious files have not been accidentally included.
File system indexing can also uncover entire directory trees, and suddenly thousands of forgotten files show up in the search index. So if you're using file system access, check for unwanted files.
Spider Activity vs. User Activity
Many other systems within a company also log and track access to the documents they contain. This should not be confused with search analytics logging; here we are talking about the logs that OTHER systems maintain to track the documents users are looking at; the spider will appear to those remote systems as a user, and they will likely log the spider's activity as well. Therefore, it's a good to have the spider identify itself when requesting pages from other servers, so that this activity can interpreted differently.
One way to flag spider activity in systems that track use accounts, such as a CMS repository, is to give the spider its own special login. Administrators will know that it's normal for the user "speedy-spider" to be reading thousands of documents.
For spiders indexing generic web servers, the easiest way to flag spider activity is to set the "User-Agent" field in the HTTP headings option of your spider configuration. The User-Agent field can even include contact information in case there is a problem, for example:
User-Agent: Internal Search Engine Spider, contact Satish at x4123
A webmaster investigating unusual access patterns will see this in their log files.
Spider "HEAD" Command and Netegrity / Site Minder
Note: This section may be a bit terse for some folks; please email us if you need a more detailed explanation.
In short, the HTTP protocol supports many request types, the two most common being GET and POST. Users will normally only use those two, and therefore in some cases these are the only two request types allowed by Netegrity by default.
However, some spiders use the HEAD request type. If your spider uses the HEAD command, and if you do use Netegrity or other SSO solutions, you should double check that this has been enabled.
Summary
There are many potential security holes that need to be double checked as you deploy an enterprise search engine. We've listed as many as we can think of, but we're always happy to hear your thoughts.
Also, if you encounter data that cannot be directly spidered, you may want to consider using Federated Search.
We hope you've enjoyed this 3 part series on designing and implementing a secure enterprise search engine. And if you missed anything, here are the links for Part 1 and Part 2.
We'd like to hear your comments and stories about search and data security. Please drop us a line!