Implementing The Taxonomy
“Ok, we have our organization taxonomy! That should make the users happy. Now everyone knows how our content is accessed”. After all that work ….Are we there yet?
Although a taxonomy is a “subject map” to an organization’s content, the map is missing the “roads”. The taxonomy can only be used to assist in accessing information if the taxonomy has been “implemented”, or assigned to content, in some way.
There are two steps to taxonomy implementation. First, every subject (classification) in the taxonomy needs to be defined to answer the question “how do I decide if the document or record belongs to this classification?”. These rules are then applied by people, or by software (various types of information retrieval or classification-categorization), or by a combination of people and automation. The degree to which the assignment is by humans or by automation is closely related to the number and variety of classifications and the amount of content.
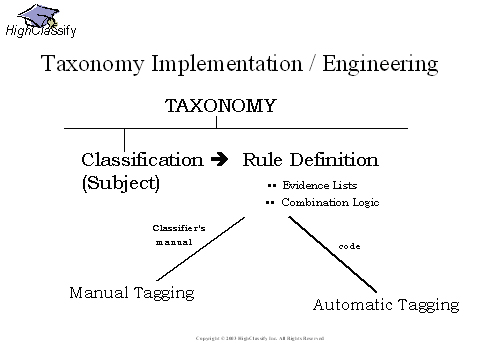
Each classification is defined by rules.
For the classification “Product X Family”, the rule is:
ANY item from the list of product models.
For the classification “Northeast Territory”, the rule is:
ANY entry from a list of states or postal codes that make up the territory.
For the classification “Joint Ventures”, the rule is
ANY entry from the terminology that represents joint ventures
PLUS
ANY entry from a list of joint venture document-record types
PLUS
ANY of the companies from a list of partners
The key to end use success is precise classifications, that are explicitly, completely and accurately defined. Without such classifications, the English language and the richness of its usage will defeat all the good intentions of a taxonomy. Classification should be able to be perfect and should be perfect. “Relative” quality (some mis-classified and some missed) will destroy your user’s confidence.
Avoid vague, qualitative or descriptive subjects in your taxonomy. Stay with subjects that are simpler, and are able to be represented by proper names, identifiers or other unique evidence. Create more and simpler classifications, rather than fewer and sophisticated classifications. The results of 20 years of organized co-operative research into better textual query have yet to produce techniques and languages that consistently find a large percentage of correct results, and simultaneously avoid a large percentage of incorrect results.
For example, a product type classification rule consists of the list of manufacturers, combined with a list of the product proper names or model identifiers. If the classification rule depends on product descriptive information, the likelihood that classification will both miss “good” material and mis-assign “bad” material is high.
Is the message that not all subjects belong in a taxonomy? Yes. If the definition isn’t obvious and precise, then the rule[s] cannot perform well, or each person being asked to classify will have to make personal, inconsistent subjective judgments.
The easy part of taxonomy implementation is the actual assignment of rules, either from a written “cookbook” for human classifiers, or software. There are basically two approaches to classification in software; those packages that accept and execute rules, and those packages that use statistical techniques (“content like this”) to construct their own rules. While the statistical vendors can fairly claim that their products avoid the “rigor” of classification definition, they also miss the precision of rules and the result vagueness that accompanies vague rules.
Since you just spent dollars and time to define rules, why ignore them? The best possible use for a statistical or learning type classification approach is after you have classified a large and varied group of document-records, either manually or with a rule-based technique.
Ongoing maintenance of classification rules is a significant but tractable activity, either in-house or from third party specialists. Rule-based classifier software will require very low maintenance. Statistical classifier software needs regular re-calibration to address new or modified classification rules.
[John Lehman is Co-Founder and President of HighClassify Inc., a provider of taxonomy and content classification services and solutions.]