What's in a name: Federated Search
We've been at this "enterprise search stuff" since the early 1990s, first as employees of other companies, and then as New Idea Engineering. This is great for our clients, but recently we goofed. We assumed we meant the same thing that they did when using a particular piece of industry jargon, "Federated Search".
For years, search vendors have used the term to describe the process of combining results from a number of different heterogeneous data sources into a single result list. For example, a federated search might send the user's search term to a search index, to a database management system, and to Google, and then combine the results from all these sources into a single result list. This is the definition we've thought of whenever anyone mentioned federated search.
But our customer - whose search team is staffed with equally bright folks - were of the opinion that a federated search meant that content from a number of different data stores would be indexed into a single search index, where users could enter queries and see results from all of the data stores would come from that one master index. Once we discovered the different usage of the term, it was easy to see how we had all misunderstood each other for the past 5 minutes. We all had a good laugh, and then went on with our meeting. For clarity, we agreed to use the term "Federated Silo Search" in the way that we (and the industry) define federated search - results from multiple sources combined into a single result list at search time. And then we would call what they had understood as federated search as "Federated Indexing Mode".
Both of these methods allow you to "federate" data from multiple sources in response to a single user query. The main design difference is which process is doing the low level indexing (and searching).
Where is the Index?
Our different understandings of federated search both produce very similar looking results - a page that shows content that resides on a number of different data store. But there are many differences technically, and as they say, "The devil is in the details".
Let's start with the traditional "Monolithic Search" that uses a Single Master Index, illustrated in Figure 1.
![[Figure 1: Diagram of Traditional Monolithic Search: Shows various data sources feeding into the Search Engine's Spider, which in turn creates the Master Search Engine Index, which is then read by the Search Application, which then sends results to the End Users. Copyright 2006, 2007 New Idea Engineering, Inc.]](/storage/newsletter-images/volume04/issue04/monolithic-search-simplified.gif)
Figure 1
The original content may reside on internal, database systems, or even in database-driven content management systems. Some companies even include data from selected external repositories in their search index, although this is less common. Typically, the search vendor's tools are used to crawl or spider the desired content sources into a single search index or collection. Once built, the search application can search the index and return consolidated results to users.
One major benefit of this Master Index / Monolithic model is that it has a single index to search. Users get quick response times without any need to access the original data sources. Since the full index integrates all of the content, relevancy algorithms apply uniformly, and dynamic navigators and parametric indices are available across all documents.
The primary negatives of the Master Index mode are related to data access and security. In order to index all content, the search engine must be able to read every document or database record. This means that the spider must have "super user" access to any data store that password-protects its content. The owner of the content has to provide an account with full access, and trust the search application will filter results based on the users credentials provide at search time. This security issue can sometimes lead to problems, especially for financial or HR content. If the engine can't gain access to particular content, then it can't search-enable it. At that point it's time for federated search.
Conventional Federated Search
For clarity, we used the term "Federated Silo Search" at our client to describe the process of sending a user query to the search function of one or more data silos - Oracle, FAST, Autonomy, Google search, CMS - and combining the results into a single result list. Figure 2 illustrates this mode.
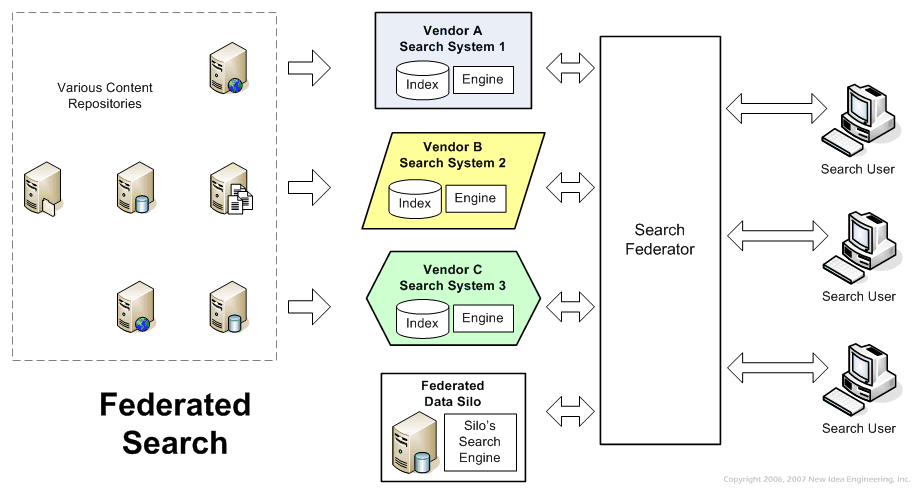
Figure 2
With federated silo search, a process called the "Search Federator" accepts the user query. The federator knows how to perform a query on each of the data source silos, so it translates the user query into the native syntax of each data source, and performs a query to the search application on each source. As far as each silo is concerned, the search request from the federator looks just like a search that would have been submitted by the user, directly to that repository; in secure applications this request will include the required native user credentials. Once each data source has responded, the search federator generates a result list and displays it to the user.
For repositories that do not include a search API, Federators can also be scripted to search using form-based content with standard HTTP GET/POST protocols. They can perform logins, fill out query forms, and then capture and parse the resulting content.
This model of federation is great when you have secure sites and do not (or cannot) provide super-user access for the spider. When the search federator sends its query, it includes the user security credentials. This means the data silo will only provide content that meets the security model.
Finally, the federated search silo model has minimum impact on the data silo - it is only accessed when a user performs a query - so there will be no period during the day when the spider provides increased load on the data source.
While the silo model solves security and forms issues, it has some disadvantages as well. Some of the challenges include:
- Translating user searches into the syntax of each underlying search engine / database
- Mapping user credentials and access rights to each of the repository security models
- Combining results that may use radically different relevancy scores
- Rendering the combined results in a pleasing and intuitive way
- Providing page-at-a-time navigation
- Combining Navigators from each result, such as faceted search, parametric search, taxonomies and auto-generate clusters
When a user enters a search, it's possible that a data silo is offline or otherwise unavailable, or that it just takes a long time to respond. Search federators typically allow you to set a timeout period, after which no results from the data silo are included in the result list. Your users may think they have all of the content available, when in fact the most important data was simply not available in time.
In addition, adding new types of data silos means scripting the new source in the federator, a skill that may have been provided by the vendor or a consulting firm during installation but which may not be a skill you have in-house. Of course, to search a silo, that silo must have some sort of search capability of its own - you cannot federate search from a web site that doesn't have search.
The real disadvantages are more subtle but just as important. Each type of silo has its own query language/syntax that the federator must be able to create; each type of data silo uses its own relevancy algorithm. How can you be confident that the first result from one source is more relevant than the first 20 results from a different data source? And technically, most search vendors use internal indices to create the dynamic navigators and perform entity extraction, so these federated sources may not be included in these Enterprise Search 2.0 features.
What About Really Secure content?
Sometimes you may find a data source in your company that is so secure that the owner does not want to allow even federated access. For example, an employee salary database may not allow any searches not initiated directly from its search form. In that case, you may want to offer special processing for searches that would be relevant to the secure data store, and use Best Bets or Search Recommendations to let the user know that other sources may have relevant content; they can go visit that repository interactively if needed.
What to do?
How do you solve the dilemma of which mode works for you? Our advice is to index as many content sources as you can in the master index. Work with site owners so they understand how you are maintaining their security, and what the benefits will be for your common users. Explain to them how your main search application implements its security.
Finally, encourage uniformity among the various types of silos, so that when you do need to use federation, you do not need to recreate new access scripts. Where possible, provide your operating divisions toolkits for each of the common types of silos.