Contrasting Relational Databases and Full-Text Search Engines
Introduction
Full-text search engines evolved much later than traditional database engines, as corporations and governments found themselves with more and more unstructured textual data in electronic format. These new text documents didn't fit well into the old table-style databases, so the need for unstructured full-text searching was apparent.
Since it was developed later, search engine technology borrowed heavily from the database world, and many search engines still employ some type of traditional table structures in their underlying architecture. Some text retrieval companies were even staffed with employees who came from traditional database company backgrounds. Many of the key RDBMS paradigms have also migrated into search engine technology, though often renamed or recast.
Overview of Full-Text Architecture
Figure 1 shows a generalized, high-level architecture of most of the commercial quality full-text engines currently available.
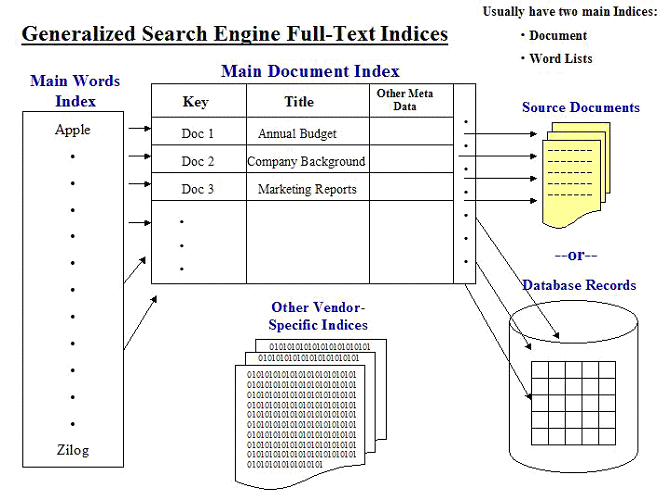
Figure 1
The indexing process begins when an application inserts data into a row in the main document index. In the simplest case, this index contains one row per document, and at a minimum contains the name of the external file or document stored in the key field. Additional field values – for example, document title – can be inserted at the same time. If the source of the data resides in a relational database, the primary key in the relational table or view goes in the main document index key field.
Once the data is inserted, the indexing engine opens the external document and creates an ordered word list to load into the main word index. The engine repeats this process for every record in the document index.
During the indexing process, each vendor will typically create other indices intended to provide additional features such as Soundex.
While searching is generally available during the indexing process, only completed records are searchable; and for performance, most engines batch together a number of records to index more efficiently.
When a query arrives, either programmatically or as a result of a user request, the full-text engine accesses the sorted and optimized word index to identify which documents contain the requested term(s). The engine creates a list of documents that qualify, typically provided as a list of pointers into the main document index.
This permits the engine to access and display a result list made up of any fields stored in the main index, calculate a relevance weight, and display a list of results.
The description of the internal architecture will be extended throughout the report.
Advantages Over Traditional Techniques
This section summarizes some of the advantages of search engines over traditional database engines. These advantages are typical of high-end search engine products.
- Optimized to Handle Textual Data
Full-text engines are specifically optimized to handle textual data. In particular, proper customer names, city, street names and other geographic markers are all textual in nature. This type of textual data is often subject to multiple valid and invalid spellings. Further, proper names are often represented in many un-normalized forms.
- Granular Index Structure
Index structure of full text engines is more granular, allowing for rapid indexed access to specific words and phrases.
- More Flexible Query Operators
Search engines offer many more query operators, such as language stemming, thesaurus, fast wildcard matches, statistically based similarity and word densities, proximity, Soundex and other "fuzzy" matching techniques.
- Hybrid Search Support
Search engines allow for hybrid searches that can search both traditional fielded data and textual data in the same query.
- Relevancy Weighting
Search engines provide relevancy weights to likely matches, allowing for much finer tuning of search results.
Technical Similarities
While relational database systems and full-text search engines are optimized to process fundamentally different types of data, there are a number of similarities between the two.
- Query Processing
For both relational and full-text engines, a query is processed and passed to the engine to retrieve data. While most relational systems use largely standard syntax, full-text systems generally use proprietary syntax. One notable exception is Fulcrum, which bases its query syntax on SQL.
- Data Loading
As with relational systems, data must be loaded into full-text systems. And like relational systems, how the data is organized and loaded can impact later success of the application. And, as with relational systems, data is loaded into full-text engines both in bulk periodically or on a record-by-record real-time basis.
- Data Indexing
Once data is loaded into relational systems, it should be indexed for optimum performance. The same is true for full-text systems, although indexing is required for any retrieval, not just to optimize performance.
Search engines create much more extensive indices than a traditional relational systems. A full-text engine typically creates an index of every word in every document, and some full-text engines index character pairs and triplets as well as full words.
Technical Differences
While there are similarities between full-text and relational technologies, there are a number of differences as well because of the fundamental differences between the types of data being indexed and the flexibility of the retrieval options. While the differences can present some challenges, they also present the opportunity to take advantage of the key features of full-text search to provide an innovative solution to the problem at hand.
- Differences in Technical Vocabulary
As mentioned, full-text and relational systems use many similar terms. For example, both relational and full-text systems use the term "index" in almost the same way, but there are some differences. These vocabulary differences are of special note for people with a relational background who start working with full-text engines.
As suggested earlier, a user or program generates a query that is passed to a relational or full-text engine, which processes the query and returns a result set. A relational system returns rows of fielded data. A full-text system returns meta-data representing documents.
A database or table in the relational world is similar, but not identical to, a collection in the full-text world. In some cases, a collection is more analogous to a relational view. What a relational system refers to as a result-set record is often referred to as a document by full-text engines.
Other terms are specific to full-text engines and vendors, and have no meaning in the relational environment.
In the same way, some concepts from the relational world are conspicuously absent from full-text environment. As we will discuss, full-text engines do not directly use joins and outer joins. Also, since full-text engines tend to serve as a read-only medium, there is much less emphasis on transactions and related mechanisms. People familiar with relational systems may be initially puzzled by their absence, given their importance in the database world.
- Data Structure
Relational engines typically store structured data such that associated data is stored in the same record or row, with the components organized into identified fields or columns of information. Formatted documents and images are maintained in special long fields such as binary long objects, although the scope of commands that can be used on these long fields is limited.
Full-text engines are optimized for processing formatted and unformatted documents, but they must also be able to process limited structured data such as document titles, authors, and descriptions. The command sets of most full-text engines are optimized for flexible retrieval of documents, with a less feature-rich set of commands to process and retrieve the structures data.
- Query Syntax
There is much wider variety of query language syntax in full-text engines. Many engines do support the classic "AND", "OR" and "NOT" operators in some form; some engines even allow for complex nested queries using parenthesis or other nesting syntax. A modern pseudo-standard is the "Internet syntax", which allows for "+" and "-" to be used as a shorthand for Boolean operators. Many search engines actually support multiple syntaxes that can often be configured when a search is performed.
- Additional Full-Text Operators
Advanced search engines typically offer a wider variety of query operators than traditional relational engines. Examples include thesaurus, language stemming, Soundex, "typo" and proximity qualifiers.
While some of these operators could be simulated with a relational database, others require special indexing of a scope and granularity well beyond that which is available in relational systems.
- Weighting
Relational queries typically return rows that match the specified query in arbitrary order, or sorted by a field specified in the query. Records that are returned match the query; and records that do not match the query are simply not returned.
Most advanced full-text engines will also retrieve only those documents that match the query, but additionally "weight" each returned document with a relevancy score, so that the results set is not just an unordered list of matching records. Typically, the weight is calculated using proprietary algorithms based on the vendor, although most engines provide syntax for affecting the final weight. Full-text queries typically return a much larger percentage "records" than a traditional query, but frequently only the higher ranking matches are of interest.
Most full-text result lists are intended for presentation to a human operator, who can evaluate attributes of the returned document – title, author, summary, or other attributes – to identify the most appropriate document.
- Different Usage Patterns
Search engine users typically issue shorter initial queries than a skilled SQL user, but will often issue subsequent refined queries to drill-down to find the most relevant documents.
- Joins
Search engines typically do not perform database joins; instead they often have a much simpler arrangement of data, perhaps somewhat analogous to relational database views.
- Outer Joins
There is no direct analog to an "outer join" in full-text engines. Any required complex data gathering tasks would usually be performed prior to indexing the full-text data..
- Simpler Table Structure in Full-Text Systems
Unlike traditional databases, a search engine administrator will typically deal with only a few document tables, referred to by most vendors as "collections", "catalogs" or "document indices". Nonetheless, full-text engines may internally be using multiple table structures to store their indices.
A hypothetical Human Resources illustration may help clarify the difference between relational databases and full-text indices.
With a relational database, HR data would be broken up into many tables. Even for a simple object model such as "employees", there may a dozen tables, relating addresses, referencing department records, tax and payroll records, and 401K records.
For a full-text engine, employees would probably be indexed in a single collection, with each "document" representing an individual employee. This document can represent a single, physical document, or perhaps more likely in this HR example, a virtual document.
- Virtual Documents
At the heart of full-text systems is the concept of a “unit of retrieval”. This is often a file or document, but when the source data is relational in nature, the unit of retrieval is typically a “virtual document” composed of data from a number of columns and tables.
In the earlier example of an HR database, a virtual document made up of a number of columns is created for each employee. This could be an actual relational view, or it could be a ‘virtual view’ created only during the full-text indexing phase. This primarily textual document might have the employee name, job skills, manager's name, and perhaps a copy of the employee’s resume. A full-text search for the employee name, the manager name, or for the skills listed in the employee’s resume would be returned. Note that a full-text collection would probably not be used for reporting purposes, or to find tax or 401K-contribution information.
Virtual documents often contain predefined regions known as “zones”, which are similar to fields. With a zone, created at index time, searches can be narrowed down more precisely. Using the earlier HR example, if the manager's name is identified as a zone at index time, a query could request only those documents where the manager’s name appears in the manager zone. Thus, a document with the manager’s name in the employee resume would not be returned in this case.
- Document Keys
As in relational systems, full-text documents are identified using a key field. In full-text systems, the document key may be a file or document name, or a URL. If the full-text system is used to index and search relational data, the document key is typically the primary key in the relational table or view.
- Data Types and Document Formats
Most full-text engines support character, numeric and data/time formats in addition to text. These fields can be used in searching, sorting and displaying results. Their use in searching is discussed below.
There is a much wider variety of native document format support with full-text engines. These documents are not just stored as "blobs"; they are actually opened and their contents indexed. Typically supported formats include text, HTML, and various 'binary' document formats such as Microsoft Word, Excel, and PowerPoint; some engines handle PDF and XML as well. Many search engines leave the original documents intact, in their original location, and store binary indices pointing to those documents.
Vocabulary Comparison Summary
Table 1 summarizes vocabulary between relational and full-text databases. Due to the large number of vendors and broad use of terms, this table can only serve as an approximation.
| RDBMS Term(s) | Full-Text Term(s) | Notes |
| database | collection, document index or catalog | Varies widely |
| table | segment or partition | This is typically transparent to the casual Search Engine administrator; you typically do not address individual partitions or segments. |
| record | document, record, page, web page or result | Traditional search engines deal in terms of "documents"; more modern Internet engines talk of "web pages" |
| field | field, document field, meta field, zone | Search engines often have two different ways of storing data. When it is stored in the document index, it is usually called a "field". When it is stored in the word index, it is usually called a "zone". Each type of storage has its own benefits |
| blob | zone | Larger segments of text are typically stored as zones |
| index (noun) | collection, document index or word index | In both worlds it typically refers to a large binary data-store residing on a disk |
| index (verb) | index or spider | The tabulating and storing of data into the binary indices |
| query | query or search | Same terminology in both |
| join | n/a | Full-text engines do not usually do "joins" at search time |
| import/export | n/a | Most full-text engines do not offer robust important and export capabilities. Some vendors do offer import tools. Though indexed, documents are typically not imported directly into a full-text database. The process of "indexing" or "spidering" can be thought of as a type of import, although the original source documents are left where they were. |
| SQL | n/a | Though there are some full-text query language standards, they are not widely supported or implemented. The closest semi-standard is the "Internet syntax" of some vendors, where + and - service as AND and NOT, quotation marks demark exact phrases, and ()'s are often recognized to convey precedence. |
| ODBC | n/a | There is no widely used standard. Most modern full-text engines do offer access via the HTTP protocol's CGI mechanism, though the specific field names to use vary widely from vendor to vendor. |
Table 1
Summary
Because full-text search engines evolved after, and borrowed heavily from, traditional database engines, administrators should feel right at home. Internalizing the new vocabulary will help complete the transition. If you find yourself still thinking about “inner and outer joins”, remember that these things need to happen up front, at index time, not at search time.