Relevancy Tuning with Autonomy IDOL
This article discusses relevancy tuning using the primary information platform from Autonomy known as the IDOL Server. Autonomy uses Bayesian inference and Shannon's information theory to determine relevance, which allows the engine to perform powerful conceptual searches, although more common search methods such as exact match are also available.
Because of the conceptual approach, tuning search results using Autonomy differs from the query cooling common with Verity K2, and we'll address three simple tuning approaches in this article.
- Boosting metadata fields during indexing
- Boosting individual documents, and
- Boosting the specific term weighting at query time.
Method 1: Boosting metadata fields during indexing
The metadata fields in documents that are indexed into Autonomy's search engine known as the Dynamic Reasoning Engine (DRE) can be weighted according to the importance of the field. This weighting is factored into the indexing process, and applies to all documents containing the specified field. For example, suppose we are creating an index of scientific books where each document contains a title field. We would like to make the title 4 times more relevant, since the text associated with the title is more important to describing the content of the book. In order to do this, we need to open up a text editor and modify the configuration file associated with the DRE.
Step # 1: Define a field process
After opening up the configuration file, we create a field process. The field process is in charge of mapping the actual field to a set of internal operations of the search engine.
[FieldProcessing]
Number=1
0=IndexandWeightHigher
Step #2: Map a field to a property
The field process needs to know the name of the field to weight higher, in this case title.
[IndexAndWeightHigher]
Property=WeightHigherProperty
PropertyFieldCSVs=*/TITLE
Step #3: Define a property
The property describes what to map the field to internal data structures. In this case we have defined a property to that will index the title field with a weight of four.
[Properties]
0=WeightHigherProperty
[WeightHigherProperty]
Index=True
Weight=4
After you've added the parameters to the configuration file, the search engine needs to be re-started by stopping and starting the application from the services console in the control panel. Once re-started, the documents should be re-indexed in order for the new weighting to take effect. You'll need to send the http command /DRERESET to the index port in order to zero out the documents in the index and then restart the spiders.
Method 2: Boosting the relevance of individual documents
In some cases you want to give a relevancy boost to individual documents based on the documents popularity. This is a standard technique employed by web search engines that assign popularity to pages by analyzing the level of connectedness between web pages. For the enterprise, the popularity of a page is often tweaked by the search engine administrator, by manually adding a popularity ranking to a document. The popularity is often determined by analyzing log files or even by monitoring clicks. Using Autonomy, the implementation of this technique requires the definition of a pre-determined field dedicated that holds the popularity of the document. Suppose you've analyzed your search logs and have a full understanding of the most accessed documents in your enterprise. You'd like to begin to tweak the search results from this information. You've also decided to weight the popularity of the document on a scale of 1 to 10 which corresponds to a 0% to 2% relevancy boost respectively. You've also decided to store the document score in a field named POPULARITY. You're now ready to start sending commands to the search engine. All commands are sent to either the index port or the query port via http.
Step#1: Add the score to the popularity field
First you'll need to add the score of the document to the POPULARITY field. To accomplish this, you'll need to send the /DREREPLACE command to the DRE and identify the document id to change along with the value of the popularity field.
For example, to give document id 200 a popularity rating of '10', the command to the DRE would be:
http://<url>:<port>/DREREPLACE?#DREDOCID 200 #DREFIELDNAME POPULARITY #DREFIELDVALUE 10
#DREENDDATA
Step #2: Add biasing to the query
Once the popularity settings have been determined for all documents of interest, we need to tell the DRE to bias the results according to the information contained in the popularity field. This involves sending the BIAS function as a parameter to the query port. The BIAS function adheres to a simple triangle function as illustrated in Figure 1 below, and is function of the form, BIAS(mean, range, percent).
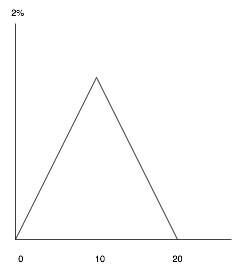
Figure 1
We want the maximum bias percentage to be 2%, so the value for percentage is 2. We've decide that the popularity rating of 10 will correspond to a 2% relevancy boost, so the mean will be 10. We also want a popularity of 0 to correspond to a 0% bias so the range is also 10. For this example, we are only using the left side of the triangle function. So when you query the DRE for information about cats, it would look the query below
http://<url>:<port>/action=query&text=cats&FieldText=BIAS{10,10,2}*/POPULARITY
The good thing about using this method is that it occurs at query time which means that you can experiment with different biasing values until satisfied.
Method 3: Boosting the Specific Term Weighting at Query Time
The final method discussed in this article involves increasing the relevance of individual terms in the query string. This is really quite easy, and no massaging of the actual data is necessary. Suppose you are interested in information concerning cheese pizza. But, you would like the documents returned to have more to do with pizza than cheese. For example, you want to decrease the relevance of documents having to do with mainly cheese , but that may mention pizza. You are mainly interested in the topic of pizza. You can tell the DRE to weight the word pizza more highly than pizza. Weighting terms follows the form, <query_term>[*<N>]. The number N can be any positive number and it corresponds to the importance of the term in the query. In the pizza example, we might choose to consider the term pizza as twice as important to the term cheese. To accomplish this, the user would send the following command to the DRE.
/action=query&text=cheese pizza[*2]
Conclusion
The techniques discussed are just two techniques that aid in the relevancy of documents returned in search results. But there are other techniques that we will be discussed in later newsletters. Stay tuned for the next part, where we discuss the use of synonyms.
KnowledgeStream specializes in implementing knowledge management solutions to help companies increase revenue and streamline costs. With technical expertise in the platform offerings from Autonomy and Plumtree, they help clients effectively manage corporate information. Email Chris or call him at 617-504-7474