Anatomy of a Search Engine
|
At the most basic level, search engines share these three logical components:
Each one of these systems is dependent on the previous system in order to function. A search engine can't run searches if there is no fulltext index. And there won't be any fulltext index if the documents were never fetched and indexed. Modern search engines have further subdivided the data prep, index and search functions into additional subsystems, in order to achieve better modularity and extreme scalability. A fully exploded component view might look like: Data Prep Spider
Cross Page Links Database Processing
Determine Mime Type Indexing
Determine Document Language Fulltext Index
Word Inversion Index Search Engine
Accept initial Query from the User Even this outline is oversimplified for larger, more complex engines. |
Traditional Monolithic Search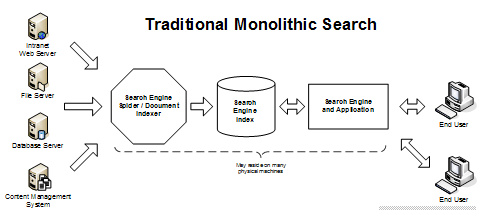 |
What's NOT a Search EngineNote that it is technically possible to search in just one step by scanning the source material line by line every time a search term is entered. This is very slow and inefficient and we do not consider these systems to be true search engines. Examples of these linear scan based "pseudo-search-engines" include:
In addition to being very slow (relative to the fulltext index based designs), these simpler pseudo engines typically don't have advanced capabilities like stemming or thesaurus support. |